Web Scrapping using python
Web scraping is a technique for gathering data or information on web pages. A scraper is a script that parses an html site. Scrapers are bound to fail in cases of site re-design.
To extract data using web scraping with python, we need to follow these basic steps:
- Find the URL that you want to scrape
- Inspecting the Page
- Find the data you want to extract
- Write the code
- Run the code and extract the data
- Store the data in the required format
Libraries used for Web Scraping
As we know, Python is has various applications and there are different libraries for different purposes. we will be using the following libraries:
Requests:- Requests is a python library designed to simplify the process of making HTTP requests. This is highly valuable for web scraping because the first step in any web scraping workflow is to send an HTTP request to the website’s server to retrieve the data displayed on the target web page.
BeautifulSoup:- BeautifulSoupis a python library designed to parse data, i.e., to extract data from HTML or XML documents. Because BeautifulSoup can only parse the data and can’t retrieve the web pages themselves, it is often used with the Requests library. In situations like these, Requests will make the HTTP request to the website to retrieve the web page, and once it has been returned, BeautifulSoup can be used to parse the target data from the HTML page.
Pandas:- pandas is a software library written for the Python programming language for data manipulation and analysis. In particular, it offers data structures and operations for manipulating numerical tables and time series.
- Find the URL that you want to scrape. I have select Filpkart mobile site.
2. Inspecting the Page
Just right click on the element and click on “Inspect”.
3. Find the data you want to extract
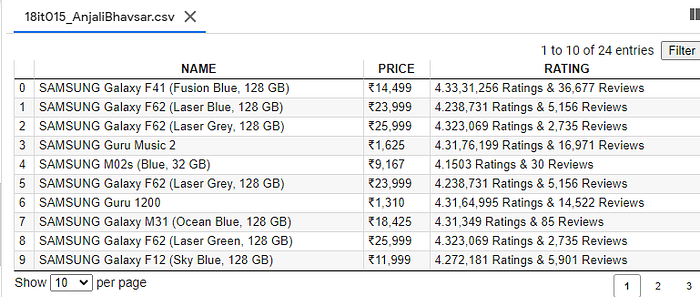
Here I have extracted the Name and model of product with specific specification, it’s price and rating. Using this parameters it can be easy for one to predict their needs.
4. Write the code
Importing the libraries:
import requests
from bs4 import BeautifulSoup
import pandas as pdopen the URL which we selected above and extract the data from the website.
url='https://www.flipkart.com/search?q=mobile&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off%27&p%5B%5D=facets.brand%255B%255D%3DSAMSUNG'
req=requests.get(url)Create empty arrays, we will use them in future for storing data of specific column.
nm=[]
pr=[]
rt=[]Using the Find and Find All methods in BeautifulSoup. We extract the data and store it in the variable.
content=BeautifulSoup(req.content,'html.parser')
name=content.find_all('div',{"class":"_4rR01T"})
price= content.find_all('div',{"class":"_30jeq3 _1_WHN1"})
rating=content.find_all('div',{"class":"gUuXy-"})Using append we store the details in the Array that we have created before
for i in name:
nm.append(i.text)
for i in price:
pr.append(i.text)
for i in rating:
rt.append(i.text)5. Store the data in the required format
Here after storing the data to the list that we have created, we have to store the data to some place from were it can be easily readable and the operation can be done to it. So we will store it to a “Comma Separated Values(.csv)” file using the following code. In this lines it is coded that in .csv file there will be three column name “ NAME”, “PRICE”, “RATING” and every data will be under this column accordingly. We have used Pandas for data manipulation.
data={'NAME':nm,'PRICE':pr,'RATING':rt}
df=pd.DataFrame(data)df.to_csv('18it015_AnjaliBhavsar.csv')6. Run the code and extract the data
After running the code, here is the 18it015_AnjaliBhavsar.csv file. In this file there are total entries of products that we have scraped .It can be very easy to perform operation on such clean data.
I put github link For complete code:
